
Grammar Coverage#
Producing inputs from grammars gives all possible expansions of a rule the same likelihood. For producing a comprehensive test suite, however, it makes more sense to maximize variety – for instance, by not repeating the same expansions over and over again. In this chapter, we explore how to systematically cover elements of a grammar such that we maximize variety and do not miss out individual elements.
from bookutils import YouTubeVideo
YouTubeVideo('GGb3e5p0HC8')
Prerequisites
You should have read the chapter on grammars.
You should have read the chapter on efficient grammar fuzzing.
Synopsis#
To use the code provided in this chapter, write
>>> from fuzzingbook.GrammarCoverageFuzzer import <identifier>
and then make use of the following features.
This chapter introduces GrammarCoverageFuzzer, an efficient grammar fuzzer extending GrammarFuzzer from the chapter on efficient grammar fuzzing. It strives to cover all expansions at least once, thus ensuring coverage of functionality.
In the following example, for instance, we use GrammarCoverageFuzzer to produce an expression. We see that the resulting expression covers all digits and all operators in a single expression.
>>> from Grammars import EXPR_GRAMMAR
>>> expr_fuzzer = GrammarCoverageFuzzer(EXPR_GRAMMAR)
>>> expr_fuzzer.fuzz()
'-(2 + 3) * 4.5 / 6 - 2.0 / +8 + 7 + 3'
After fuzzing, the expansion_coverage() method returns a mapping of grammar expansions covered.
>>> expr_fuzzer.expansion_coverage()
{'<digit> -> 0',
'<digit> -> 1',
'<digit> -> 2',
'<digit> -> 3',
'<digit> -> 4',
'<digit> -> 5',
'<digit> -> 6',
'<digit> -> 7',
'<digit> -> 8',
'<digit> -> 9',
'<expr> -> <term>',
'<expr> -> <term> + <expr>',
'<expr> -> <term> - <expr>',
'<factor> -> (<expr>)',
'<factor> -> +<factor>',
'<factor> -> -<factor>',
'<factor> -> <integer>',
'<factor> -> <integer>.<integer>',
'<integer> -> <digit>',
'<integer> -> <digit><integer>',
'<start> -> <expr>',
'<term> -> <factor>',
'<term> -> <factor> * <term>',
'<term> -> <factor> / <term>'}
Subsequent calls to fuzz() will go for further coverage (i.e., covering the other area code digits, for example); a call to reset() clears the recorded coverage, starting anew.
Since such coverage in inputs also yields higher code coverage, GrammarCoverageFuzzer is a recommended extension to GrammarFuzzer.

Covering Grammar Elements#
The aim of test generation is to cover all functionality of a program – hopefully including the failing functionality, of course. This functionality, however, is tied to the structure of the input: If we fail to produce certain input elements, then the associated code and functionality will not be triggered either, nixing our chances to find a bug in there.
As an example, consider our expression grammar EXPR_GRAMMAR from the chapter on grammars.:
If we do not produce negative numbers, then negative numbers will not be tested.
If we do not produce floating-point numbers, then floating-point numbers will not be tested.
Our aim must thus be to cover all possible expansions – and not only by chance, but by design.
One way to maximize such variety is to track the expansions that occur during grammar production: If we already have seen some expansion, we can prefer other possible expansion candidates out of the set of possible expansions. Consider the following rule in our expression grammar:
import bookutils.setup
from bookutils import quiz
from Fuzzer import Fuzzer
from typing import Dict, List, Set, Union, Optional
from Grammars import EXPR_GRAMMAR, CGI_GRAMMAR, URL_GRAMMAR, START_SYMBOL
from Grammars import is_valid_grammar, extend_grammar, Grammar
EXPR_GRAMMAR["<factor>"]
['+<factor>', '-<factor>', '(<expr>)', '<integer>.<integer>', '<integer>']
Let us assume we have already produced an <integer> in the first expansion of <factor>. As it comes to expand the next factor, we would mark the <integer> expansion as already covered, and choose one of the yet uncovered alternatives such as -<factor> (a negative number) or <integer>.<integer> (a floating-point number). Only when we have covered all alternatives would we go back and reconsider expansions covered before.
quiz("Which expansions of `EXPR_GRAMMAR` does the expression `1 + 2` cover?",
[
"`<start> -> <expr>`",
"`<integer> -> <digit><integer>`",
"`<integer> -> <digit>`",
"`<factor> -> +<factor>`"
], [1, 3])
Quiz
EXPR_GRAMMAR does the expression 1 + 2 cover?
Indeed! The expression has expansions from <start> and into individual digits.
Tracking Grammar Coverage#
This concept of grammar coverage is easy to implement. We introduce a class TrackingGrammarCoverageFuzzer that keeps track of the current grammar coverage achieved:
from Grammars import Grammar, Expansion
from GrammarFuzzer import GrammarFuzzer, all_terminals, nonterminals, \
display_tree, DerivationTree
import random
class TrackingGrammarCoverageFuzzer(GrammarFuzzer):
"""Track grammar coverage during production"""
def __init__(self, *args, **kwargs) -> None:
# invoke superclass __init__(), passing all arguments
super().__init__(*args, **kwargs)
self.reset_coverage()
Keeping Track of Expansions#
In the set covered_expansions, we store individual expansions seen.
class TrackingGrammarCoverageFuzzer(TrackingGrammarCoverageFuzzer):
def expansion_coverage(self) -> Set[str]:
"""Return the set of covered expansions as strings SYMBOL -> EXPANSION"""
return self.covered_expansions
def reset_coverage(self) -> None:
"""Clear coverage info tracked so far"""
self.covered_expansions: Set[str] = set()
We save them the expansions as strings “symbol -> expansion”, using the function expansion_key() to generate a string representation for the (symbol, expansion) pair.
def expansion_key(symbol: str,
expansion: Union[Expansion,
DerivationTree,
List[DerivationTree]]) -> str:
"""Convert (symbol, `expansion`) into a key "SYMBOL -> EXPRESSION".
`expansion` can be an expansion string, a derivation tree,
or a list of derivation trees."""
if isinstance(expansion, tuple):
# Expansion or single derivation tree
expansion, _ = expansion
if not isinstance(expansion, str):
# Derivation tree
children = expansion
expansion = all_terminals((symbol, children))
assert isinstance(expansion, str)
return symbol + " -> " + expansion
Here’s an example:
expansion_key(START_SYMBOL, EXPR_GRAMMAR[START_SYMBOL][0])
'<start> -> <expr>'
Instead of expansion, we can also pass a list of children as argument, which will then automatically be converted into a string.
children: List[DerivationTree] = [("<expr>", None), (" + ", []), ("<term>", None)]
expansion_key("<expr>", children)
'<expr> -> <expr> + <term>'
Computing Possible Expansions#
We can compute the set of possible expansions in a grammar by enumerating all expansions. The method max_expansion_coverage() traverses the grammar recursively starting from the given symbol (by default: the grammar start symbol) and accumulates all expansions in the set expansions. With the max_depth parameter (default: \(\infty\)), we can control how deep the grammar exploration should go; we will need this later in the chapter.
class TrackingGrammarCoverageFuzzer(TrackingGrammarCoverageFuzzer):
def _max_expansion_coverage(self, symbol: str,
max_depth: Union[int, float]) -> Set[str]:
if max_depth <= 0:
return set()
self._symbols_seen.add(symbol)
expansions = set()
for expansion in self.grammar[symbol]:
expansions.add(expansion_key(symbol, expansion))
for nonterminal in nonterminals(expansion):
if nonterminal not in self._symbols_seen:
expansions |= self._max_expansion_coverage(
nonterminal, max_depth - 1)
return expansions
def max_expansion_coverage(self, symbol: Optional[str] = None,
max_depth: Union[int, float] = float('inf')) \
-> Set[str]:
"""Return set of all expansions in a grammar
starting with `symbol` (default: start symbol).
If `max_depth` is given, expand only to that depth."""
if symbol is None:
symbol = self.start_symbol
self._symbols_seen: Set[str] = set()
cov = self._max_expansion_coverage(symbol, max_depth)
if symbol == START_SYMBOL:
assert len(self._symbols_seen) == len(self.grammar)
return cov
We can use max_expansion_coverage() to compute all the expansions within the expression grammar:
expr_fuzzer = TrackingGrammarCoverageFuzzer(EXPR_GRAMMAR)
expr_fuzzer.max_expansion_coverage()
{'<digit> -> 0',
'<digit> -> 1',
'<digit> -> 2',
'<digit> -> 3',
'<digit> -> 4',
'<digit> -> 5',
'<digit> -> 6',
'<digit> -> 7',
'<digit> -> 8',
'<digit> -> 9',
'<expr> -> <term>',
'<expr> -> <term> + <expr>',
'<expr> -> <term> - <expr>',
'<factor> -> (<expr>)',
'<factor> -> +<factor>',
'<factor> -> -<factor>',
'<factor> -> <integer>',
'<factor> -> <integer>.<integer>',
'<integer> -> <digit>',
'<integer> -> <digit><integer>',
'<start> -> <expr>',
'<term> -> <factor>',
'<term> -> <factor> * <term>',
'<term> -> <factor> / <term>'}
Tracking Expansions while Fuzzing#
During expansion, we can keep track of expansions seen. To do so, we hook into the method choose_node_expansion(), expanding a single node in our Grammar fuzzer.
class TrackingGrammarCoverageFuzzer(TrackingGrammarCoverageFuzzer):
def add_coverage(self, symbol: str,
new_child: Union[Expansion, List[DerivationTree]]) -> None:
key = expansion_key(symbol, new_child)
if self.log and key not in self.covered_expansions:
print("Now covered:", key)
self.covered_expansions.add(key)
def choose_node_expansion(self, node: DerivationTree,
children_alternatives:
List[List[DerivationTree]]) -> int:
(symbol, children) = node
index = super().choose_node_expansion(node, children_alternatives)
self.add_coverage(symbol, children_alternatives[index])
return index
The method missing_expansion_coverage() is a helper method that returns the expansions that still have to be covered:
class TrackingGrammarCoverageFuzzer(TrackingGrammarCoverageFuzzer):
def missing_expansion_coverage(self) -> Set[str]:
"""Return expansions not covered yet"""
return self.max_expansion_coverage() - self.expansion_coverage()
Putting Things Together#
Let us show how tracking works. To keep things simple, let us focus on <digit> expansions only.
digit_fuzzer = TrackingGrammarCoverageFuzzer(
EXPR_GRAMMAR, start_symbol="<digit>", log=True)
digit_fuzzer.fuzz()
Tree: <digit>
Expanding <digit> randomly
Now covered: <digit> -> 9
Tree: 9
'9'
'9'
digit_fuzzer.fuzz()
Tree: <digit>
Expanding <digit> randomly
Now covered: <digit> -> 0
Tree: 0
'0'
'0'
digit_fuzzer.fuzz()
Tree: <digit>
Expanding <digit> randomly
Now covered: <digit> -> 5
Tree: 5
'5'
'5'
Here’s the set of covered expansions so far:
digit_fuzzer.expansion_coverage()
{'<digit> -> 0', '<digit> -> 5', '<digit> -> 9'}
This is the set of all expansions we can cover:
digit_fuzzer.max_expansion_coverage()
{'<digit> -> 0',
'<digit> -> 1',
'<digit> -> 2',
'<digit> -> 3',
'<digit> -> 4',
'<digit> -> 5',
'<digit> -> 6',
'<digit> -> 7',
'<digit> -> 8',
'<digit> -> 9'}
This is the missing coverage:
digit_fuzzer.missing_expansion_coverage()
{'<digit> -> 1',
'<digit> -> 2',
'<digit> -> 3',
'<digit> -> 4',
'<digit> -> 6',
'<digit> -> 7',
'<digit> -> 8'}
On average, how many characters do we have to produce until all expansions are covered?
def average_length_until_full_coverage(fuzzer: TrackingGrammarCoverageFuzzer) -> float:
trials = 50
sum = 0
for trial in range(trials):
# print(trial, end=" ")
fuzzer.reset_coverage()
while len(fuzzer.missing_expansion_coverage()) > 0:
s = fuzzer.fuzz()
sum += len(s)
return sum / trials
digit_fuzzer.log = False
average_length_until_full_coverage(digit_fuzzer)
28.4
For full expressions, this takes a bit longer:
expr_fuzzer = TrackingGrammarCoverageFuzzer(EXPR_GRAMMAR)
average_length_until_full_coverage(expr_fuzzer)
138.12
Covering Grammar Expansions#
Let us now not only track coverage, but actually produce coverage. The idea is as follows:
We determine children yet uncovered (in
uncovered_children)If all children are covered, we fall back to the original method (i.e., choosing one expansion randomly)
Otherwise, we select a child from the uncovered children and mark it as covered.
To this end, we introduce a new fuzzer SimpleGrammarCoverageFuzzer that implements this strategy in the choose_node_expansion() method – the method the GrammarFuzzer superclass uses to select the child to be expanded.
class SimpleGrammarCoverageFuzzer(TrackingGrammarCoverageFuzzer):
"""When choosing expansions, prefer expansions not covered."""
def choose_node_expansion(self,
node: DerivationTree,
children_alternatives: List[List[DerivationTree]]) -> int:
"""Return index of expansion in `children_alternatives` to be selected.
Picks uncovered expansions, if any."""
# Prefer uncovered expansions
(symbol, children) = node
uncovered_children = [c for (i, c) in enumerate(children_alternatives)
if expansion_key(symbol, c)
not in self.covered_expansions]
index_map = [i for (i, c) in enumerate(children_alternatives)
if c in uncovered_children]
if len(uncovered_children) == 0:
# All expansions covered - use superclass method
return self.choose_covered_node_expansion(node, children_alternatives)
# Select from uncovered nodes
index = self.choose_uncovered_node_expansion(node, uncovered_children)
return index_map[index]
The two methods choose_covered_node_expansion() and choose_uncovered_node_expansion() are provided for subclasses to hook in:
class SimpleGrammarCoverageFuzzer(SimpleGrammarCoverageFuzzer):
def choose_uncovered_node_expansion(self,
node: DerivationTree,
children_alternatives: List[List[DerivationTree]]) \
-> int:
"""Return index of expansion in _uncovered_ `children_alternatives`
to be selected.
To be overloaded in subclasses."""
return TrackingGrammarCoverageFuzzer.choose_node_expansion(
self, node, children_alternatives)
def choose_covered_node_expansion(self,
node: DerivationTree,
children_alternatives: List[List[DerivationTree]]) \
-> int:
"""Return index of expansion in _covered_ `children_alternatives`
to be selected.
To be overloaded in subclasses."""
return TrackingGrammarCoverageFuzzer.choose_node_expansion(
self, node, children_alternatives)
By returning the set of expansions covered so far, we can invoke the fuzzer multiple times, each time adding to the grammar coverage. Using the EXPR_GRAMMAR grammar to produce digits, for instance, the fuzzer produces one digit after the other:
f = SimpleGrammarCoverageFuzzer(EXPR_GRAMMAR, start_symbol="<digit>")
f.fuzz()
'5'
f.fuzz()
'2'
f.fuzz()
'1'
Here’s the set of covered expansions so far:
f.expansion_coverage()
{'<digit> -> 1', '<digit> -> 2', '<digit> -> 5'}
Let us fuzz some more. We see that with each iteration, we cover another expansion:
for i in range(7):
print(f.fuzz(), end=" ")
0 9 7 4 8 3 6
At the end, all expansions are covered:
f.missing_expansion_coverage()
set()
Let us apply this on a more complex grammar – e.g., the full expression grammar. We see that after a few iterations, we cover each and every digit, operator, and expansion:
f = SimpleGrammarCoverageFuzzer(EXPR_GRAMMAR)
for i in range(10):
print(f.fuzz())
+(0.31 / (5) / 9 + 4 * 6 / 3 - 8 - 7) * -2
+++2 / 87360
((4) * 0 - 1) / -9.6 + 7 / 6 + 1 * 8 + 7 * 8
++++26 / -64.45
(8 / 1 / 6 + 9 + 7 + 8) * 1.1 / 0 * 1
7.7
++(3.5 / 3) - (-4 + 3) / (8 / 0) / -4 * 2 / 1
+(90 / --(28 * 8 / 5 + 5 / (5 / 8))) - +9.36 / 2.5 * (5 * (7 * 6 * 5) / 8)
9.11 / 7.28
1 / (9 - 5 * 6) / 6 / 7 / 7 + 1 + 1 - 7 * -3
Again, all expansions are covered:
f.missing_expansion_coverage()
set()
We see that our strategy is much more effective in achieving coverage than the random approach:
average_length_until_full_coverage(SimpleGrammarCoverageFuzzer(EXPR_GRAMMAR))
52.28
Deep Foresight#
Selecting expansions for individual rules is a good start; however, it is not sufficient, as the following example shows. We apply our coverage fuzzer on the CGI grammar from the chapter on grammars:
CGI_GRAMMAR
{'<start>': ['<string>'],
'<string>': ['<letter>', '<letter><string>'],
'<letter>': ['<plus>', '<percent>', '<other>'],
'<plus>': ['+'],
'<percent>': ['%<hexdigit><hexdigit>'],
'<hexdigit>': ['0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'a',
'b',
'c',
'd',
'e',
'f'],
'<other>': ['0', '1', '2', '3', '4', '5', 'a', 'b', 'c', 'd', 'e', '-', '_']}
f = SimpleGrammarCoverageFuzzer(CGI_GRAMMAR)
for i in range(10):
print(f.fuzz())
c
+%a6++
+-
+
++
%18%b7
+e
_
d2+%e3
%d0
After 10 iterations, we still have a number of expansions uncovered:
f.missing_expansion_coverage()
{'<hexdigit> -> 2',
'<hexdigit> -> 4',
'<hexdigit> -> 5',
'<hexdigit> -> 9',
'<hexdigit> -> c',
'<hexdigit> -> f',
'<other> -> 0',
'<other> -> 1',
'<other> -> 3',
'<other> -> 4',
'<other> -> 5',
'<other> -> a',
'<other> -> b'}
Why is that so? The problem is that in the CGI grammar, the largest number of variations to be covered occurs in the hexdigit rule. However, we first need to reach this expansion. When expanding a <letter> symbol, we have the choice between three possible expansions:
CGI_GRAMMAR["<letter>"]
['<plus>', '<percent>', '<other>']
If all three expansions are covered already, then choose_node_expansion() above will choose one randomly – even if there may be more expansions to cover when choosing <percent>.
What we need is a better strategy that will pick <percent> if there are more uncovered expansions following – even if <percent> is covered. Such a strategy was first discussed by W. Burkhardt \cite{Burkhardt1967} under the name of “Shortest Path Selection”:
This version selects, from several alternatives for development, that syntactic unit under which there is still an unused unit available, starting with the shortest path.
This is what we will implement in the next steps.
Determining Maximum per-Symbol Coverage#
To address this problem, we introduce a new class GrammarCoverageFuzzer that builds on SimpleGrammarCoverageFuzzer, but with a better strategy. First, we need to compute the maximum set of expansions that can be reached from a particular symbol, as we already have implemented in max_expansion_coverage(). The idea is to later compute the intersection of this set and the expansions already covered, such that we can favor those expansions with a non-empty intersection.
The first step – computing the maximum set of expansions that can be reached from a symbol – is already implemented. By passing a symbol parameter to max_expansion_coverage(), we can compute the possible expansions for every symbol:
f = SimpleGrammarCoverageFuzzer(EXPR_GRAMMAR)
f.max_expansion_coverage('<integer>')
{'<digit> -> 0',
'<digit> -> 1',
'<digit> -> 2',
'<digit> -> 3',
'<digit> -> 4',
'<digit> -> 5',
'<digit> -> 6',
'<digit> -> 7',
'<digit> -> 8',
'<digit> -> 9',
'<integer> -> <digit>',
'<integer> -> <digit><integer>'}
We see that by expanding <integer>, we can cover a total of 12 productions.
quiz("How many productions would `f.max_expansion_coverage('<digit>')` return?",
[
"10",
"11",
"12",
"13"
], "100 / 100")
Quiz
f.max_expansion_coverage('<digit>') return?
Indeed. Here are all the possible expansions for <digit>:
f.max_expansion_coverage('<digit>')
{'<digit> -> 0',
'<digit> -> 1',
'<digit> -> 2',
'<digit> -> 3',
'<digit> -> 4',
'<digit> -> 5',
'<digit> -> 6',
'<digit> -> 7',
'<digit> -> 8',
'<digit> -> 9'}
Determining yet Uncovered Children#
We can now start to implement GrammarCoverageFuzzer. Our idea is to determine the missing coverage for each child.
Given a list of children, we can use max_expansion_coverage() to compute the maximum coverage for each child. From this, we subtract the coverage already seen (expansion_coverage()). This results in the coverage we can still obtain.
class GrammarCoverageFuzzer(SimpleGrammarCoverageFuzzer):
"""Produce from grammars, aiming for coverage of all expansions."""
def new_child_coverage(self,
symbol: str,
children: List[DerivationTree],
max_depth: Union[int, float] = float('inf')) -> Set[str]:
"""Return new coverage that would be obtained
by expanding (`symbol`, `children`)"""
new_cov = self._new_child_coverage(children, max_depth)
new_cov.add(expansion_key(symbol, children))
new_cov -= self.expansion_coverage() # -= is set subtraction
return new_cov
def _new_child_coverage(self, children: List[DerivationTree],
max_depth: Union[int, float]) -> Set[str]:
new_cov: Set[str] = set()
for (c_symbol, _) in children:
if c_symbol in self.grammar:
new_cov |= self.max_expansion_coverage(c_symbol, max_depth)
return new_cov
Let us illustrate new_child_coverage(). We again start fuzzing, choosing expansions randomly.
f = GrammarCoverageFuzzer(EXPR_GRAMMAR, start_symbol="<digit>", log=True)
f.fuzz()
Tree: <digit>
Expanding <digit> randomly
Now covered: <digit> -> 2
Tree: 2
'2'
'2'
This is our current coverage:
f.expansion_coverage()
{'<digit> -> 2'}
# docassert
assert f.expansion_coverage() == {'<digit> -> 2'}
If we want to expand <digit> into 0, that would yield us new coverage:
f.new_child_coverage("<digit>", [('0', [])])
{'<digit> -> 0'}
If we want to expand <digit> into 2 again, that would yield us no new coverage:
f.new_child_coverage("<digit>", [('2', [])])
set()
When we go through the individual expansion possibilities for <digit>, we see that all expansions offer additional coverage, except for the 2 we have already covered.
for expansion in EXPR_GRAMMAR["<digit>"]:
children = f.expansion_to_children(expansion)
print(expansion, f.new_child_coverage("<digit>", children))
0 {'<digit> -> 0'}
1 {'<digit> -> 1'}
2 set()
3 {'<digit> -> 3'}
4 {'<digit> -> 4'}
5 {'<digit> -> 5'}
6 {'<digit> -> 6'}
7 {'<digit> -> 7'}
8 {'<digit> -> 8'}
9 {'<digit> -> 9'}
This means that whenever choosing an expansion, we can make use of new_child_coverage() and choose among the expansions that offer the greatest new (unseen) coverage.
Adaptive Lookahead#
When choosing a child, we do not look out for the maximum overall coverage to be obtained, as this would have expansions with many uncovered possibilities totally dominate other expansions. Instead, we aim for a breadth-first strategy, first covering all expansions up to a given depth, and only then looking for a greater depth.
The method new_coverages() is at the heart of this strategy: Starting with a maximum depth (max_depth) of zero, it increases the depth until it finds at least one uncovered expansion.
Excursion: Implementing new_coverage()#
class GrammarCoverageFuzzer(GrammarCoverageFuzzer):
def new_coverages(self, node: DerivationTree,
children_alternatives: List[List[DerivationTree]]) \
-> Optional[List[Set[str]]]:
"""Return coverage to be obtained for each child at minimum depth"""
(symbol, children) = node
for max_depth in range(len(self.grammar)):
new_coverages = [
self.new_child_coverage(
symbol, c, max_depth) for c in children_alternatives]
max_new_coverage = max(len(new_coverage)
for new_coverage in new_coverages)
if max_new_coverage > 0:
# Uncovered node found
return new_coverages
# All covered
return None
End of Excursion#
All Together#
We can now define choose_node_expansion() to make use of this strategy:
We determine the possible coverages to be obtained (using
new_coverages())We (randomly) select among the children which sport the maximum coverage (using
choose_uncovered_node_expansion()).
Excursion: Implementing choose_node_expansion()#
class GrammarCoverageFuzzer(GrammarCoverageFuzzer):
def choose_node_expansion(self, node: DerivationTree,
children_alternatives: List[List[DerivationTree]]) -> int:
"""Choose an expansion of `node` among `children_alternatives`.
Return `n` such that expanding `children_alternatives[n]`
yields the highest additional coverage."""
(symbol, children) = node
new_coverages = self.new_coverages(node, children_alternatives)
if new_coverages is None:
# All expansions covered - use superclass method
return self.choose_covered_node_expansion(node, children_alternatives)
max_new_coverage = max(len(cov) for cov in new_coverages)
children_with_max_new_coverage = [c for (i, c) in enumerate(children_alternatives)
if len(new_coverages[i]) == max_new_coverage]
index_map = [i for (i, c) in enumerate(children_alternatives)
if len(new_coverages[i]) == max_new_coverage]
# Select a random expansion
new_children_index = self.choose_uncovered_node_expansion(
node, children_with_max_new_coverage)
new_children = children_with_max_new_coverage[new_children_index]
# Save the expansion as covered
key = expansion_key(symbol, new_children)
if self.log:
print("Now covered:", key)
self.covered_expansions.add(key)
return index_map[new_children_index]
End of Excursion#
With this, our GrammarCoverageFuzzer is now complete! Let us apply it on a series of examples. On expressions, it quickly covers all digits and operators:
f = GrammarCoverageFuzzer(EXPR_GRAMMAR, min_nonterminals=3)
f.fuzz()
'-4.02 / (1) * +3 + 5.9 / 7 * 8 - 6'
f.max_expansion_coverage() - f.expansion_coverage()
set()
On average, it is again faster than the simple strategy:
average_length_until_full_coverage(GrammarCoverageFuzzer(EXPR_GRAMMAR))
50.74
On the CGI grammar, it takes but a few iterations to cover all letters and digits:
f = GrammarCoverageFuzzer(CGI_GRAMMAR, min_nonterminals=5)
while len(f.max_expansion_coverage() - f.expansion_coverage()) > 0:
print(f.fuzz())
%18%d03
%c3%94%7f+cd
%a6%b5%e2%5e%4c-54e01a2
%5eb%7cb_ec%a0+
This improvement can also be seen in comparing the random, expansion-only, and deep foresight strategies on the CGI grammar:
average_length_until_full_coverage(TrackingGrammarCoverageFuzzer(CGI_GRAMMAR))
211.34
average_length_until_full_coverage(SimpleGrammarCoverageFuzzer(CGI_GRAMMAR))
68.64
average_length_until_full_coverage(GrammarCoverageFuzzer(CGI_GRAMMAR))
40.38
Coverage in Context#
Sometimes, grammar elements are used in more than just one place. In our expression grammar, for instance, the <integer> symbol is used for integer numbers as well as for floating point numbers:
EXPR_GRAMMAR["<factor>"]
['+<factor>', '-<factor>', '(<expr>)', '<integer>.<integer>', '<integer>']
Our coverage production, as defined above, will ensure that all <integer> expansions (i.e., all <digit> expansions) are covered. However, the individual digits would be distributed across all occurrences of <integer> in the grammar. If our coverage-based fuzzer produces, say, 1234.56 and 7890, we would have full coverage of all digit expansions. However, <integer>.<integer> and <integer> in the <factor> expansions above would individually cover only a fraction of the digits. If floating-point numbers and whole numbers have different functions that read them in, we would like each of these functions to be tested with all digits; maybe we would also like the whole and fractional part of a floating-point number to be tested with all digits each.
Ignoring the context in which a symbol is used (in our case, the various uses of <integer> and <digit> in the <factor> context) can be useful if we can assume that all occurrences of this symbol are treated alike anyway. If not, though, one way to ensure that an occurrence of a symbol is systematically covered independently of other occurrences is to assign the occurrence to a new symbol which is a duplicate of the old symbol. We will first show how to manually create such duplicates, and then a dedicated function which does it automatically.
Extending Grammars for Context Coverage Manually#
As stated above, one simple way to achieve coverage in context is by duplicating symbols as well as the rules they reference to. For instance, we could replace <integer>.<integer> by <integer-1>.<integer-2> and give <integer-1> and <integer-2> the same definitions as the original <integer>. This would mean that not only all expansions of <integer>, but also all expansions of <integer-1> and <integer-2> would be covered.
Let us illustrate this with actual code:
dup_expr_grammar = extend_grammar(EXPR_GRAMMAR,
{
"<factor>": ["+<factor>", "-<factor>", "(<expr>)", "<integer-1>.<integer-2>", "<integer>"],
"<integer-1>": ["<digit-1><integer-1>", "<digit-1>"],
"<integer-2>": ["<digit-2><integer-2>", "<digit-2>"],
"<digit-1>":
["0", "1", "2", "3", "4",
"5", "6", "7", "8", "9"],
"<digit-2>":
["0", "1", "2", "3", "4",
"5", "6", "7", "8", "9"]
}
)
assert is_valid_grammar(dup_expr_grammar)
If we now run our coverage-based fuzzer on the extended grammar, we will cover all digits both of regular integers, and all digits in the whole and fraction part of floating-point numbers:
f = GrammarCoverageFuzzer(dup_expr_grammar, start_symbol="<factor>")
for i in range(10):
print(f.fuzz())
-(43.76 / 8.0 * 5.5 / 6.9 * 6 / 4 + +03)
(90.1 - 1 * 7.3 * 9 + 5 / 8 / 7)
2.8
1.2
10.4
2
4386
7
0
08929.4302
We see how our “foresighted” coverage fuzzer specifically generates floating-point numbers that cover all digits both in the whole and fractional parts.
Extending Grammars for Context Coverage Programmatically#
If we want to enhance coverage in context, manually adapting our grammars may not be the perfect choice, since any change to the grammar will have to be replicated in all duplicates. Instead, we introduce a function that will do the duplication for us.
The function duplicate_context() takes a grammar, a symbol in the grammar, and an expansion of this symbol (None or not given: all expansions of symbol), and it changes the expansion to refer to a duplicate of all originally referenced rules. The idea is that we invoke it as
dup_expr_grammar = extend_grammar(EXPR_GRAMMAR)
duplicate_context(dup_expr_grammar, "<factor>", "<integer>.<integer>")
and get a similar result as with our manual changes, above.
Here is the code:
from Grammars import new_symbol, unreachable_nonterminals
from GrammarFuzzer import expansion_to_children
def duplicate_context(grammar: Grammar,
symbol: str,
expansion: Optional[Expansion] = None,
depth: Union[float, int] = float('inf')):
"""Duplicate an expansion within a grammar.
In the given grammar, take the given expansion of the given `symbol`
(if `expansion` is omitted: all symbols), and replace it with a
new expansion referring to a duplicate of all originally referenced rules.
If `depth` is given, limit duplication to `depth` references
(default: unlimited)
"""
orig_grammar = extend_grammar(grammar)
_duplicate_context(grammar, orig_grammar, symbol,
expansion, depth, seen={})
# After duplication, we may have unreachable rules; delete them
for nonterminal in unreachable_nonterminals(grammar):
del grammar[nonterminal]
Excursion: Implementing _duplicate_context()#
The bulk of the work takes place in this helper function. The additional parameter seen keeps track of symbols already expanded and avoids infinite recursion.
import copy
def _duplicate_context(grammar: Grammar,
orig_grammar: Grammar,
symbol: str,
expansion: Optional[Expansion],
depth: Union[float, int],
seen: Dict[str, str]) -> None:
"""Helper function for `duplicate_context()`"""
for i in range(len(grammar[symbol])):
if expansion is None or grammar[symbol][i] == expansion:
new_expansion = ""
for (s, c) in expansion_to_children(grammar[symbol][i]):
if s in seen: # Duplicated already
new_expansion += seen[s]
elif c == [] or depth == 0: # Terminal symbol or end of recursion
new_expansion += s
else: # Nonterminal symbol - duplicate
# Add new symbol with copy of rule
new_s = new_symbol(grammar, s)
grammar[new_s] = copy.deepcopy(orig_grammar[s])
# Duplicate its expansions recursively
# {**seen, **{s: new_s}} is seen + {s: new_s}
_duplicate_context(grammar, orig_grammar, new_s, expansion=None,
depth=depth - 1, seen={**seen, **{s: new_s}})
new_expansion += new_s
grammar[symbol][i] = new_expansion
End of Excursion#
Here’s our above example of how duplicate_context() works, now with results. We let it duplicate the <integer>.<integer> expansion in our expression grammar, and obtain a new grammar with an <integer-1>.<integer-2> expansion where both <integer-1> and <integer-2> refer to copies of the original rules:
dup_expr_grammar = extend_grammar(EXPR_GRAMMAR)
duplicate_context(dup_expr_grammar, "<factor>", "<integer>.<integer>")
dup_expr_grammar
{'<start>': ['<expr>'],
'<expr>': ['<term> + <expr>', '<term> - <expr>', '<term>'],
'<term>': ['<factor> * <term>', '<factor> / <term>', '<factor>'],
'<factor>': ['+<factor>',
'-<factor>',
'(<expr>)',
'<integer-1>.<integer-2>',
'<integer>'],
'<integer>': ['<digit><integer>', '<digit>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<integer-1>': ['<digit-1><integer-1>', '<digit-2>'],
'<digit-1>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<digit-2>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<integer-2>': ['<digit-3><integer-2>', '<digit-4>'],
'<digit-3>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<digit-4>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']}
Just like above, using such a grammar for coverage fuzzing will now cover digits in a number of contexts. To be precise, there are five contexts: Regular integers, as well as single-digit and multi-digit whole and fractional parts of floating-point numbers.
f = GrammarCoverageFuzzer(dup_expr_grammar, start_symbol="<factor>")
for i in range(10):
print(f.fuzz())
(57.5)
2
+-(1 / 3 + 6 / 0 - 7 * 59 * 3 + 8 * 4)
374.88
5.709
0.93
01.1
892.27
219.50
6.636
The depth parameter controls how deep the duplication should go. Setting depth to 1 will duplicate only the next rule:
dup_expr_grammar = extend_grammar(EXPR_GRAMMAR)
duplicate_context(dup_expr_grammar, "<factor>", "<integer>.<integer>", depth=1)
dup_expr_grammar
{'<start>': ['<expr>'],
'<expr>': ['<term> + <expr>', '<term> - <expr>', '<term>'],
'<term>': ['<factor> * <term>', '<factor> / <term>', '<factor>'],
'<factor>': ['+<factor>',
'-<factor>',
'(<expr>)',
'<integer-1>.<integer-2>',
'<integer>'],
'<integer>': ['<digit><integer>', '<digit>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<integer-1>': ['<digit><integer-1>', '<digit>'],
'<integer-2>': ['<digit><integer-2>', '<digit>']}
assert is_valid_grammar(dup_expr_grammar)
By default, depth is set to \(\infty\), indicating unlimited duplication. True unbounded duplication could lead to problems for a recursive grammar such as EXPR_GRAMMAR, so duplicate_context() is set to no longer duplicate symbols once duplicated. Still, if we apply it to duplicate all <expr> expansions, we obtain a grammar with no less than 292 rules:
dup_expr_grammar = extend_grammar(EXPR_GRAMMAR)
duplicate_context(dup_expr_grammar, "<expr>")
assert is_valid_grammar(dup_expr_grammar)
len(dup_expr_grammar)
292
This gives us almost 2000 expansions to cover:
f = GrammarCoverageFuzzer(dup_expr_grammar)
len(f.max_expansion_coverage())
1981
Duplicating one more time keeps on both growing the grammar and the coverage requirements:
dup_expr_grammar = extend_grammar(EXPR_GRAMMAR)
duplicate_context(dup_expr_grammar, "<expr>")
duplicate_context(dup_expr_grammar, "<expr-1>")
len(dup_expr_grammar)
594
f = GrammarCoverageFuzzer(dup_expr_grammar)
len(f.max_expansion_coverage())
3994
At this point, plenty of contexts can be covered individually – for instance, multiplications of elements within additions:
dup_expr_grammar["<expr>"]
['<term-1> + <expr-4>', '<term-5> - <expr-8>', '<term-9>']
dup_expr_grammar["<term-1-1>"]
['<factor-1-1> * <term-1-1>', '<factor-2-1> / <term-1-1>', '<factor-3-1>']
dup_expr_grammar["<factor-1-1>"]
['+<factor-1-1>',
'-<factor-1-1>',
'(<expr-1-1>)',
'<integer-1-1>.<integer-2-1>',
'<integer-3-1>']
The resulting grammars may no longer be useful for human maintenance; but running a coverage-driven fuzzer such as GrammarCoverageFuzzer() will then go and cover all these expansions in all contexts. If you want to cover elements in many contexts, then duplicate_context() followed by a coverage-driven fuzzer is your friend.
Covering Code by Covering Grammars#
With or without context: By systematically covering all input elements, we get a larger variety in our inputs – but does this translate into a wider variety of program behaviors? After all, these behaviors are what we want to cover, including the unexpected behaviors.
In a grammar, there are elements that directly correspond to program features. A program handling arithmetic expressions will have functionality that is directly triggered by individual elements - say, an addition feature triggered by the presence of +, subtraction triggered by the presence of -, and floating-point arithmetic triggered by the presence of floating-point numbers in the input.
Such a connection between input structure and functionality leads to a strong correlation between grammar coverage and code coverage. In other words: If we can achieve a high grammar coverage, this also leads to a high code coverage.
CGI Grammars#
Let us explore this relationship on one of our grammars – say, the CGI decoder from the chapter on coverage.
Excursion: Creating the Plot#
We compute a mapping coverages where in coverages[x] = {y_1, y_2, ...}, x is the grammar coverage obtained, and y_n is the code coverage obtained for the n-th run.
We first compute the maximum coverage, as in the chapter on coverage:
from Coverage import Coverage, cgi_decode
with Coverage() as cov_max:
cgi_decode('+')
cgi_decode('%20')
cgi_decode('abc')
try:
cgi_decode('%?a')
except:
pass
Now, we run our experiment:
f = GrammarCoverageFuzzer(CGI_GRAMMAR, max_nonterminals=2)
coverages: Dict[float, List[float]] = {}
trials = 100
for trial in range(trials):
f.reset_coverage()
overall_cov = set()
max_cov = 30
for i in range(10):
s = f.fuzz()
with Coverage() as cov:
cgi_decode(s)
overall_cov |= cov.coverage()
x = len(f.expansion_coverage()) * 100 / len(f.max_expansion_coverage())
y = len(overall_cov) * 100 / len(cov_max.coverage())
if x not in coverages:
coverages[x] = []
coverages[x].append(y)
We compute the averages for the y-values:
xs = list(coverages.keys())
ys = [sum(coverages[x]) / len(coverages[x]) for x in coverages]
and create a scatter plot:
%matplotlib inline
import matplotlib.pyplot as plt # type: ignore
import matplotlib.ticker as mtick # type: ignore
ax = plt.axes(label="CGI coverage")
ax.yaxis.set_major_formatter(mtick.PercentFormatter())
ax.xaxis.set_major_formatter(mtick.PercentFormatter())
plt.xlim(0, max(xs))
plt.ylim(0, max(ys))
plt.title('Coverage of cgi_decode() vs. grammar coverage')
plt.xlabel('grammar coverage (expansions)')
plt.ylabel('code coverage (lines)')
Text(0, 0.5, 'code coverage (lines)')
End of Excursion#
This scatter plot shows the relationship between grammar coverage (X axis) and code coverage (Y axis).
# ignore
plt.scatter(xs, ys);
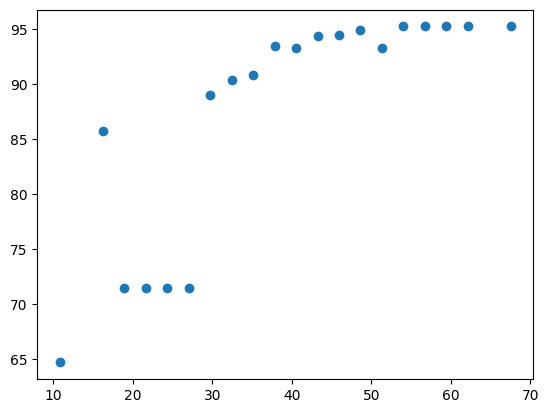
We see that the higher the grammar coverage, the higher the code coverage.
This also translates into a correlation coefficient of about 0.9, indicating a strong correlation:
import numpy as np
np.corrcoef(xs, ys)
array([[1. , 0.81663071],
[0.81663071, 1. ]])
This is also confirmed by the Spearman rank correlation:
from scipy.stats import spearmanr # type: ignore
spearmanr(xs, ys)
SignificanceResult(statistic=np.float64(0.9477544699285101), pvalue=np.float64(2.2771918715723359e-10))
URL Grammars#
Let us repeat this experiment on URL grammars. We use the same code as above, except for exchanging the grammars and the function in place:
from urllib.parse import urlparse
Excursion: Creating the Plot#
Again, we first compute the maximum coverage, making an educated guess as in the chapter on coverage:
with Coverage() as cov_max:
urlparse("http://foo.bar/path")
urlparse("https://foo.bar#fragment")
urlparse("ftp://user:password@foo.bar?query=value")
urlparse("ftps://127.0.0.1/?x=1&y=2")
Here comes the actual experiment:
f = GrammarCoverageFuzzer(URL_GRAMMAR, max_nonterminals=2)
coverages: Dict[float, List[float]] = {}
trials = 100
for trial in range(trials):
f.reset_coverage()
overall_cov = set()
for i in range(20):
s = f.fuzz()
with Coverage() as cov:
urlparse(s)
overall_cov |= cov.coverage()
x = len(f.expansion_coverage()) * 100 / len(f.max_expansion_coverage())
y = len(overall_cov) * 100 / len(cov_max.coverage())
if x not in coverages:
coverages[x] = []
coverages[x].append(y)
xs = list(coverages.keys())
ys = [sum(coverages[x]) / len(coverages[x]) for x in coverages]
ax = plt.axes(label="URL coverage")
ax.yaxis.set_major_formatter(mtick.PercentFormatter())
ax.xaxis.set_major_formatter(mtick.PercentFormatter())
plt.xlim(0, max(xs))
plt.ylim(0, max(ys))
plt.title('Coverage of urlparse() vs. grammar coverage')
plt.xlabel('grammar coverage (expansions)')
plt.ylabel('code coverage (lines)')
Text(0, 0.5, 'code coverage (lines)')
End of Excursion#
This scatter plot shows the relationship between grammar coverage (X axis) and code coverage (Y axis).
plt.scatter(xs, ys);
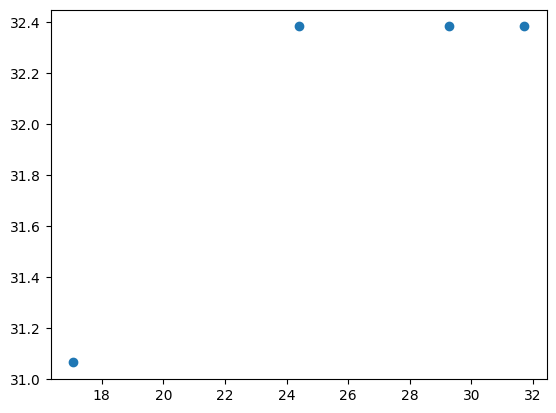
Here, we have an even stronger correlation of more than .95:
np.corrcoef(xs, ys)
array([[1. , 0.8819171],
[0.8819171, 1. ]])
This is also confirmed by the Spearman rank correlation:
spearmanr(xs, ys)
SignificanceResult(statistic=np.float64(0.9486832980505139), pvalue=np.float64(0.05131670194948612))
We conclude: If one wants to obtain high code coverage, it is a good idea to strive for high grammar coverage first.
Will this always work?#
The correlation observed for the CGI and URL examples will not hold for every program and every structure.
Equivalent Elements#
First, some grammar elements are treated uniformly by a program even though the grammar sees them as different symbols. In the host name of a URL, for instance, we can have many characters, although a URL-handling program treats them all the same. Likewise, individual digits, once composed into a number, make less of a difference than the value of the number itself. Hence, achieving variety in digits or characters will not necessarily yield a large difference in functionality.
This problem can be addressed by differentiating elements dependent on their context, and covering alternatives for each context, as discussed above. The key is to identify the contexts in which variety is required, and those where it is not.
Deep Data Processing#
Second, the way the data is processed can make a large difference. Consider the input to a media player, consisting of compressed media data. While processing the media data, the media player will show differences in behavior (notably in its output), but these differences cannot be directly triggered through individual elements of the media data. Likewise, a machine learner that is trained on a large set of inputs typically will not have its behavior controlled by a single syntactic element of the input. (Well, it could, but then, we would not need a machine learner.) In these cases of “deep” data processing, achieving structural coverage in the grammar will not necessarily induce code coverage.
One way to address this problem is to achieve not only syntactic, but actually semantic variety. In the chapter on fuzzing with constraints, we will see how to specifically generate and filter input values, especially numerical values. Such generators can also be applied in context, such that each and every facet of the input can be controlled individually. Also, in the above examples, some parts of the input can still be covered structurally: Metadata (such as author name or composer for the media player) or configuration data (such as settings for the machine learner) can and should be covered systematically; we will see how this is done in the chapter on “Configuration fuzzing”.
Synopsis#
This chapter introduces GrammarCoverageFuzzer, an efficient grammar fuzzer extending GrammarFuzzer from the chapter on efficient grammar fuzzing. It strives to cover all expansions at least once, thus ensuring coverage of functionality.
In the following example, for instance, we use GrammarCoverageFuzzer to produce an expression. We see that the resulting expression covers all digits and all operators in a single expression.
from Grammars import EXPR_GRAMMAR
expr_fuzzer = GrammarCoverageFuzzer(EXPR_GRAMMAR)
# ignore
expr_fuzzer.fuzz();
expr_fuzzer.fuzz()
'-(2 + 3) * 4.5 / 6 - 2.0 / +8 + 7 + 3'
After fuzzing, the expansion_coverage() method returns a mapping of grammar expansions covered.
expr_fuzzer.expansion_coverage()
{'<digit> -> 0',
'<digit> -> 1',
'<digit> -> 2',
'<digit> -> 3',
'<digit> -> 4',
'<digit> -> 5',
'<digit> -> 6',
'<digit> -> 7',
'<digit> -> 8',
'<digit> -> 9',
'<expr> -> <term>',
'<expr> -> <term> + <expr>',
'<expr> -> <term> - <expr>',
'<factor> -> (<expr>)',
'<factor> -> +<factor>',
'<factor> -> -<factor>',
'<factor> -> <integer>',
'<factor> -> <integer>.<integer>',
'<integer> -> <digit>',
'<integer> -> <digit><integer>',
'<start> -> <expr>',
'<term> -> <factor>',
'<term> -> <factor> * <term>',
'<term> -> <factor> / <term>'}
Subsequent calls to fuzz() will go for further coverage (i.e., covering the other area code digits, for example); a call to reset() clears the recorded coverage, starting anew.
Since such coverage in inputs also yields higher code coverage, GrammarCoverageFuzzer is a recommended extension to GrammarFuzzer.
# ignore
from ClassDiagram import display_class_hierarchy
# ignore
display_class_hierarchy([GrammarCoverageFuzzer],
public_methods=[
Fuzzer.run,
Fuzzer.runs,
GrammarFuzzer.__init__,
GrammarFuzzer.fuzz,
GrammarFuzzer.fuzz_tree,
TrackingGrammarCoverageFuzzer.max_expansion_coverage,
TrackingGrammarCoverageFuzzer.missing_expansion_coverage,
TrackingGrammarCoverageFuzzer.reset_coverage,
GrammarCoverageFuzzer.__init__,
GrammarCoverageFuzzer.fuzz,
GrammarCoverageFuzzer.expansion_coverage,
],
types={
'DerivationTree': DerivationTree,
'Expansion': Expansion,
'Grammar': Grammar
},
project='fuzzingbook')
Lessons Learned#
Achieving grammar coverage quickly results in a large variety of inputs.
Duplicating grammar rules allows covering elements in specific contexts.
Achieving grammar coverage can help in obtaining code coverage.
Next Steps#
From here, you can learn how to
Background#
The idea of ensuring that each expansion in the grammar is used at least once goes back to Burkhardt \cite{Burkhardt1967}, to be later rediscovered by Paul Purdom \cite{Purdom1972}. The relation between grammar coverage and code coverage was discovered by Nikolas Havrikov, who explores it in his PhD thesis.
Exercises#
Exercise 1: Testing ls#
Consider the Unix ls program, used to list the contents of a directory. Create a grammar for invoking ls:
LS_EBNF_GRAMMAR: Grammar = {
'<start>': ['-<options>'],
'<options>': ['<option>*'],
'<option>': ['1', 'A', '@',
# many more
]
}
assert is_valid_grammar(LS_EBNF_GRAMMAR)
Use GrammarCoverageFuzzer to test all options. Be sure to invoke ls with each option set.
Solution. We can copy the set of option characters right from the manual page:
from Grammars import convert_ebnf_grammar, srange
LS_EBNF_GRAMMAR: Grammar = {
'<start>': ['-<options>'],
'<options>': ['<option>*'],
'<option>': srange("ABCFGHLOPRSTUW@abcdefghiklmnopqrstuwx1")
}
assert is_valid_grammar(LS_EBNF_GRAMMAR)
LS_GRAMMAR: Grammar = convert_ebnf_grammar(LS_EBNF_GRAMMAR)
from Fuzzer import ProgramRunner
f = GrammarCoverageFuzzer(LS_GRAMMAR, max_nonterminals=3)
while len(f.max_expansion_coverage() - f.expansion_coverage()) > 0:
invocation = f.fuzz()
print("ls", invocation, end="; ")
args = invocation.split()
ls = ProgramRunner(["ls"] + args)
ls.run()
print()
ls -; ls -Wgx; ls -qe; ls -1cC; ls -tL; ls -slUn; ls -imF; ls -SB; ls -PTo; ls -hHb; ls -pdk@; ls -AO; ls -rG; ls -wa; ls -fu; ls -Rc;
By setting max_nonterminals to other values, you can control how many options ls should be invoked with. We will see more of such examples in the chapter on configuration testing.
Exercise 2: Caching#
The value of max_expansion_coverage() depends on the grammar only. Change the implementation such that the values are precomputed for each symbol and depth upon initialization (__init__()); this way, max_expansion_coverage() can simply look up the value in the table.
Solution. This is like exercise 1 and 2 in the chapter on efficient grammar fuzzing; you can implement a similar solution here.